![]()
Databricks-Certified-Data-Engineer-Professional Exam Dumps Pass with Updated 2025 Certified Exam Questions
Databricks-Certified-Data-Engineer-Professional Exam Questions - Real & Updated Questions PDF
NEW QUESTION # 32
Which statement describes Delta Lake optimized writes?
- A. Optimized writes logical partitions instead of directory partitions partition boundaries are only Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from represented in metadata fewer small files are written.
- B. Before a job cluster terminates, OPTIMIZE is executed on all tables modified during the most recent job.
- C. A shuffle occurs prior to writing to try to group data together resulting in fewer files instead of each executor writing multiple files based on directory partitions.
- D. An asynchronous job runs after the write completes to detect if files could be further compacted; yes, an OPTIMIZE job is executed toward a default of 1 GB.
Answer: C
Explanation:
Delta Lake optimized writes involve a shuffle operation before writing out data to the Delta table.
The shuffle operation groups data by partition keys, which can lead to a reduction in the number of output files and potentially larger files, instead of multiple smaller files. This approach can significantly reduce the total number of files in the table, improve read performance by reducing the metadata overhead, and optimize the table storage layout, especially for workloads with many small files.
NEW QUESTION # 33
A DLT pipeline includes the following streaming tables:
Raw_lot ingest raw device measurement data from a heart rate tracking device. Bgm_stats incrementally computes user statistics based on BPM measurements from raw_lot. How can the data engineer configure this pipeline to be able to retain manually deleted or updated records in the raw_iot table while recomputing the downstream table when a pipeline update is run?
- A. Set the SkipChangeCommits flag to true raw_lot
- B. Set the skipChangeCommits flag to true on bpm_stats
- C. Set the pipelines, reset, allowed property to false on raw_iot
- D. Set the pipelines, reset, allowed property to false on bpm_stats
Answer: C
Explanation:
In Databricks Lakehouse, to retain manually deleted or updated records in the raw_iot table while recomputing downstream tables when a pipeline update is run, the property pipelines.reset.allowed should be set to false. This property prevents the system from resetting the state of the table, which includes the removal of the history of changes, during a pipeline update. By keeping this property as false, any changes to the raw_iot table, including manual deletes or updates, are retained, and recomputation of downstream tables, such as bpm_stats, can occur with the full history of data changes intact.
NEW QUESTION # 34
The data engineering team is migrating an enterprise system with thousands of tables and views into the Lakehouse. They plan to implement the target architecture using a series of bronze, silver, and gold tables. Bronze tables will almost exclusively be used by production data engineering workloads, while silver tables will be used to support both data engineering and machine learning workloads. Gold tables will largely serve business intelligence and reporting purposes. While personal identifying information (PII) exists in all tiers of data, pseudonymization and anonymization rules are in place for all data at the silver and gold levels.
The organization is interested in reducing security concerns while maximizing the ability to collaborate across diverse teams.
Which statement exemplifies best practices for implementing this system?
- A. Because all tables must live in the same storage containers used for the database they're created in, organizations should be prepared to create between dozens and thousands of databases depending on their data isolation requirements.
- B. Because databases on Databricks are merely a logical construct, choices around database organization do not impact security or discoverability in the Lakehouse.
- C. Working in the default Databricks database provides the greatest security when working with managed tables, as these will be created in the DBFS root.
- D. Isolating tables in separate databases based on data quality tiers allows for easy permissions management through database ACLs and allows physical separation of default storage locations for managed tables.
- E. Storinq all production tables in a single database provides a unified view of all data assets available throughout the Lakehouse, simplifying discoverability by granting all users view privileges on this database.
Answer: D
Explanation:
This is the correct answer because it exemplifies best practices for implementing this system. By isolating tables in separate databases based on data quality tiers, such as bronze, silver, and gold, the data engineering team can achieve several benefits. First, they can easily manage permissions for different users and groups through database ACLs, which allow granting or revoking access to databases, tables, or views. Second, they can physically separate the default storage locations for managed tables in each database, which can improve performance and reduce costs. Third, they can provide a clear and consistent naming convention for the tables in each database, which can improve discoverability and usability.
NEW QUESTION # 35
A production workload incrementally applies updates from an external Change Data Capture feed to a Delta Lake table as an always-on Structured Stream job. When data was initially migrated for this table, OPTIMIZE was executed and most data files were resized to 1 GB. Auto Optimize and Auto Compaction were both turned on for the streaming production job. Recent review of data files shows that most data files are under 64 MB, although each partition in the table contains at least 1 GB of data and the total table size is over 10 TB.
Which of the following likely explains these smaller file sizes?
- A. Databricks has autotuned to a smaller target file size based on the overall size of data in the table
- B. Databricks has autotuned to a smaller target file size to reduce duration of MERGE operations
- C. Databricks has autotuned to a smaller target file size based on the amount of data in each partition
- D. Z-order indices calculated on the table are preventing file compaction C Bloom filler indices calculated on the table are preventing file compaction
Answer: B
Explanation:
Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from This is the correct answer because Databricks has a feature called Auto Optimize, which automatically optimizes the layout of Delta Lake tables by coalescing small files into larger ones and sorting data within each file by a specified column. However, Auto Optimize also considers the trade- off between file size and merge performance, and may choose a smaller target file size to reduce the duration of merge operations, especially for streaming workloads that frequently update existing records. Therefore, it is possible that Auto Optimize has autotuned to a smaller target file size based on the characteristics of the streaming production job.
NEW QUESTION # 36
What is the first of a Databricks Python notebook when viewed in a text editor?
- A. # MAGIC %python
- B. -- Databricks notebook source
- C. %python
- D. // Databricks notebook source
- E. # Databricks notebook source
Answer: E
Explanation:
https://docs.databricks.com/en/notebooks/notebook-export-import.html#import-a-file-and-convert- it-to-a-notebook
NEW QUESTION # 37
A data ingestion task requires a one-TB JSON dataset to be written out to Parquet with a target Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from part- file size of 512 MB. Because Parquet is being used instead of Delta Lake, built-in file-sizing features such as Auto-Optimize & Auto-Compaction cannot be used.
Which strategy will yield the best performance without shuffling data?
- A. Set spark.sql.shuffle.partitions to 2,048 partitions (1TB*1024*1024/512), ingest the data, execute the narrow transformations, optimize the data by sorting it (which automatically repartitions the data), and then write to parquet.
- B. Set spark.sql.files.maxPartitionBytes to 512 MB, ingest the data, execute the narrow transformations, and then write to parquet.
- C. Set spark.sql.shuffle.partitions to 512, ingest the data, execute the narrow transformations, and then write to parquet.
- D. Ingest the data, execute the narrow transformations, repartition to 2,048 partitions (1TB*
1024*1024/512), and then write to parquet. - E. Set spark.sql.adaptive.advisoryPartitionSizeInBytes to 512 MB bytes, ingest the data, execute the narrow transformations, coalesce to 2,048 partitions (1TB*1024*1024/512), and then write to parquet.
Answer: A
Explanation:
The key to efficiently converting a large JSON dataset to Parquet files of a specific size without shuffling data lies in controlling the size of the output files directly. Setting spark.sql.files.maxPartitionBytes to 512 MB configures Spark to process data in chunks of 512 MB. This setting directly influences the size of the part-files in the output, aligning with the target file size.
Narrow transformations (which do not involve shuffling data across partitions) can then be applied to this data.
Writing the data out to Parquet will result in files that are approximately the size specified by spark.sql.files.maxPartitionBytes, in this case, 512 MB. The other options involve unnecessary shuffles or repartitions (B, C, D) or an incorrect setting for this specific requirement (E).
NEW QUESTION # 38
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df. The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Incremental state information should be maintained for 10 minutes for late-arriving data.
Streaming DataFrame df has the following schema:
"device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT"
Code block:
Choose the response that correctly fills in the blank within the code block to complete this task.
- A. await("event_time + `10 minutes'")
- B. delayWrite("event_time", "10 minutes")
- C. slidingWindow("event_time", "10 minutes")
- D. withWatermark("event_time", "10 minutes")
- E. awaitArrival("event_time", "10 minutes")
Answer: D
Explanation:
This is because the question asks for incremental state information to be maintained for 10 minutes for late-arriving data. The withWatermark method is used to define the watermark for late data. The watermark is a timestamp column and a threshold that tells the system how long to wait for late data. In this case, the watermark is set to 10 minutes. The other options are incorrect because they are not valid methods or syntax for watermarking in Structured Streaming.
NEW QUESTION # 39
Which statement describes Delta Lake Auto Compaction?
- A. Before a Jobs cluster terminates, optimize is executed on all tables modified during the most recent job.
Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from - B. An asynchronous job runs after the write completes to detect if files could be further compacted; if yes, an optimize job is executed toward a default of 128 MB.
- C. An asynchronous job runs after the write completes to detect if files could be further compacted; if yes, an optimize job is executed toward a default of 1 GB.
- D. Data is queued in a messaging bus instead of committing data directly to memory; all data is committed from the messaging bus in one batch once the job is complete.
- E. Optimized writes use logical partitions instead of directory partitions; because partition boundaries are only represented in metadata, fewer small files are written.
Answer: B
Explanation:
This is the correct answer because it describes the behavior of Delta Lake Auto Compaction, which is a feature that automatically optimizes the layout of Delta Lake tables by coalescing small files into larger ones. Auto Compaction runs as an asynchronous job after a write to a table has succeeded and checks if files within a partition can be further compacted. If yes, it runs an optimize job with a default target file size of 128 MB. Auto Compaction only compacts files that have not been compacted previously.
NEW QUESTION # 40
The data architect has mandated that all tables in the Lakehouse should be configured as external Delta Lake tables.
Which approach will ensure that this requirement is met?
- A. When the workspace is being configured, make sure that external cloud object storage has been mounted.
- B. Whenever a database is being created, make sure that the location keyword is used Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from
- C. Whenever a table is being created, make sure that the location keyword is used.
- D. When configuring an external data warehouse for all table storage. leverage Databricks for all ELT.
- E. When tables are created, make sure that the external keyword is used in the create table statement.
Answer: C
Explanation:
This is the correct answer because it ensures that this requirement is met. The requirement is that all tables in the Lakehouse should be configured as external Delta Lake tables. An external table is a table that is stored outside of the default warehouse directory and whose metadata is not managed by Databricks. An external table can be created by using the location keyword to specify the path to an existing directory in a cloud storage system, such as DBFS or S3. By creating external tables, the data engineering team can avoid losing data if they drop or overwrite the table, as well as leverage existing data without moving or copying it.
NEW QUESTION # 41
A table in the Lakehouse named customer_churn_params is used in churn prediction by the machine learning team. The table contains information about customers derived from a number of upstream sources. Currently, the data engineering team populates this table nightly by overwriting the table with the current valid values derived from upstream data sources.
The churn prediction model used by the ML team is fairly stable in production. The team is only interested in making predictions on records that have changed in the past 24 hours.
Which approach would simplify the identification of these changed records?
- A. Apply the churn model to all rows in the customer_churn_params table, but implement logic to perform an upsert into the predictions table that ignores rows where predictions have not changed.
- B. Convert the batch job to a Structured Streaming job using the complete output mode; configure a Structured Streaming job to read from the customer_churn_params table and incrementally predict against the churn model.
- C. Replace the current overwrite logic with a merge statement to modify only those records that have changed; write logic to make predictions on the changed records identified by the change data feed.
- D. Modify the overwrite logic to include a field populated by calling
spark.sql.functions.current_timestamp() as data are being written; use this field to identify records written on a particular date. - E. Calculate the difference between the previous model predictions and the current customer_churn_params on a key identifying unique customers before making new predictions; only make predictions on those customers not in the previous predictions.
Answer: C
Explanation:
The approach that would simplify the identification of the changed records is to replace the current overwrite logic with a merge statement to modify only those records that have changed, and write logic to make predictions on the changed records identified by the change data feed.
This approach leverages the Delta Lake features of merge and change data feed, which are designed to handle upserts and track row-level changes in a Delta table. By using merge, the data engineering team can avoid overwriting the entire table every night, and only update or insert the records that have changed in the source data. By using change data feed, the ML team can easily access the change events that have occurred in the customer_churn_params table, and filter them by operation type (update or insert) and timestamp. This way, they can only make predictions on the records that have changed in the past 24 hours, and avoid re-processing the unchanged records.
NEW QUESTION # 42
A user wants to use DLT expectations to validate that a derived table report contains all records from the source, included in the table validation_copy.
The user attempts and fails to accomplish this by adding an expectation to the report table definition.
Which approach would allow using DLT expectations to validate all expected records are present in this table?
- A. Define a temporary table that perform a left outer join on validation_copy and report, and define an expectation that no report key values are null
- B. Define a view that performs a left outer join on validation_copy and report, and reference this view in DLT expectations for the report table
- C. Define a SQL UDF that performs a left outer join on two tables, and check if this returns null values for report key values in a DLT expectation for the report table.
- D. Define a function that performs a left outer join on validation_copy and report and report, and check against the result in a DLT expectation for the report table
Answer: B
Explanation:
To validate that all records from the source are included in the derived table, creating a view that performs a left outer join between the validation_copy table and the report table is effective. The view can highlight any discrepancies, such as null values in the report table's key columns, indicating missing records. This view can then be referenced in DLT (Delta Live Tables) expectations for the report table to ensure data integrity. This approach allows for a comprehensive comparison between the source and the derived table.
NEW QUESTION # 43
A Databricks job has been configured with 3 tasks, each of which is a Databricks notebook. Task A does not depend on other tasks. Tasks B and C run in parallel, with each having a serial dependency on Task A.
If task A fails during a scheduled run, which statement describes the results of this run?
- A. Tasks B and C will attempt to run as configured; any changes made in task A will be rolled back due to task failure.
- B. Unless all tasks complete successfully, no changes will be committed to the Lakehouse; because task A failed, all commits will be rolled back automatically.
- C. Because all tasks are managed as a dependency graph, no changes will be committed to the Lakehouse until all tasks have successfully been completed.
- D. Tasks B and C will be skipped; task A will not commit any changes because of stage failure.
- E. Tasks B and C will be skipped; some logic expressed in task A may have been committed before task failure.
Answer: E
Explanation:
When a Databricks job runs multiple tasks with dependencies, the tasks are executed in a dependency graph. If a task fails, the downstream tasks that depend on it are skipped and marked as Upstream failed. However, the failed task may have already committed some changes to the Lakehouse before the failure occurred, and those changes are not rolled back automatically. Therefore, the job run may result in a partial update of the Lakehouse. To avoid this, you can use the transactional writes feature of Delta Lake to ensure that the changes are only committed when the entire job run succeeds. Alternatively, you can use the Run if condition to configure tasks to run even when some or all of their dependencies have failed, allowing your job to recover from failures and continue running.
NEW QUESTION # 44
The view updates represents an incremental batch of all newly ingested data to be inserted or Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from updated in the customers table.
The following logic is used to process these records.
MERGE INTO customers
USING (
SELECT updates.customer_id as merge_ey, updates .*
FROM updates
UNION ALL
SELECT NULL as merge_key, updates .*
FROM updates JOIN customers
ON updates.customer_id = customers.customer_id
WHERE customers.current = true AND updates.address <> customers.address ) staged_updates ON customers.customer_id = mergekey WHEN MATCHED AND customers. current = true AND customers.address <> staged_updates.address THEN UPDATE SET current = false, end_date = staged_updates.effective_date WHEN NOT MATCHED THEN INSERT (customer_id, address, current, effective_date, end_date) VALUES (staged_updates.customer_id, staged_updates.address, true, staged_updates.effective_date, null) Which statement describes this implementation?
- A. The customers table is implemented as a Type 0 table; all writes are append only with no changes to existing values.
- B. The customers table is implemented as a Type 1 table; old values are overwritten by new values and no history is maintained.
- C. The customers table is implemented as a Type 2 table; old values are maintained but marked as no longer current and new values are inserted.
- D. The customers table is implemented as a Type 2 table; old values are overwritten and new customers are appended.
Answer: C
Explanation:
The provided MERGE statement is a classic implementation of a Type 2 SCD in a data warehousing context. In this approach, historical data is preserved by keeping old records (marking them as not current) and adding new records for changes. Specifically, when a match is found and there's a change in the address, the existing record in the customers table is updated to mark it as no longer current (current = false), and an end date is assigned (end_date = staged_updates.effective_date). A new record for the customer is then inserted with the updated information, marked as current. This method ensures that the full history of changes to customer information is maintained in the table, allowing for time-based analysis of customer data.
NEW QUESTION # 45
Assuming that the Databricks CLI has been installed and configured correctly, which Databricks CLI command can be used to upload a custom Python Wheel to object storage mounted with the DBFS for use with a production job?
- A. jobs
- B. workspace
- C. libraries
- D. configure
- E. fs
Answer: E
Explanation:
https://docs.databricks.com/en/archive/dev-tools/cli/dbfs-cli.html
NEW QUESTION # 46
A Data engineer wants to run unit's tests using common Python testing frameworks on python functions defined across several Databricks notebooks currently used in production. How can the data engineer run unit tests against function that work with data in production?
- A. Define and import unit test functions from a separate Databricks notebook
- B. Define and unit test functions using Files in Repos
- C. Run unit tests against non-production data that closely mirrors production
- D. Define units test and functions within the same notebook
Answer: C
Explanation:
The best practice for running unit tests on functions that interact with data is to use a dataset that closely mirrors the production data. This approach allows data engineers to validate the logic of their functions without the risk of affecting the actual production data. It's important to have a representative sample of production data to catch edge cases and ensure the functions will work correctly when used in a production environment.
NEW QUESTION # 47
Where in the Spark UI can one diagnose a performance problem induced by not leveraging predicate push-down?
- A. In the Stage's Detail screen, in the Completed Stages table, by noting the size of data read from the Input column
- B. In the Storage Detail screen, by noting which RDDs are not stored on disk
- C. In the Delta Lake transaction log. by noting the column statistics
- D. In the Executor's log file, by gripping for "predicate push-down"
- E. In the Query Detail screen, by interpreting the Physical Plan
Answer: E
Explanation:
This is the correct answer because it is where in the Spark UI one can diagnose a performance problem induced by not leveraging predicate push-down. Predicate push-down is an optimization technique that allows filtering data at the source before loading it into memory or processing it further. This can improve performance and reduce I/O costs by avoiding reading unnecessary data. To leverage predicate push-down, one should use supported data sources and formats, such as Delta Lake, Parquet, or JDBC, and use filter expressions that can be pushed down to the source. To diagnose a performance problem induced by not leveraging predicate push-down, one can use the Spark UI to access the Query Detail screen, which shows information about a SQL query executed on a Spark cluster. The Query Detail screen includes the Physical Plan, which is the actual plan executed by Spark to perform the query. The Physical Plan shows the physical operators used by Spark, such as Scan, Filter, Project, or Aggregate, and their input and output statistics, such as rows and bytes. By interpreting the Physical Plan, one can see if the filter expressions are pushed down to the source or not, and how much data is read or processed by each operator.
NEW QUESTION # 48
A data team's Structured Streaming job is configured to calculate running aggregates for item sales to update a downstream marketing dashboard. The marketing team has introduced a new field to track the number of times this promotion code is used for each item. A junior data engineer suggests updating the existing query as follows: Note that proposed changes are in bold.
Original query:
Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from
Proposed query:
Proposed query:
.start("/item_agg")
Which step must also be completed to put the proposed query into production?
- A. Specify a new checkpointlocation
- B. Increase the shuffle partitions to account for additional aggregates
- C. Run REFRESH TABLE delta, /item_agg'
- D. Register the data in the "/item_agg" directory to the Hive metastore
- E. Remove .option (mergeSchema', true') from the streaming write
Answer: A
Explanation:
When introducing a new aggregation or a change in the logic of a Structured Streaming query, it is generally necessary to specify a new checkpoint location. This is because the checkpoint directory contains metadata about the offsets and the state of the aggregations of a streaming query. If the logic of the query changes, such as including a new aggregation field, the state information saved in the current checkpoint would not be compatible with the new logic, potentially leading to incorrect results or failures. Therefore, to accommodate the new field and ensure the streaming job has the correct starting point and state information for aggregations, a new checkpoint location should be specified.
NEW QUESTION # 49
The data governance team is reviewing code used for deleting records for compliance with GDPR. They note the following logic is used to delete records from the Delta Lake table named users.
Assuming that user_id is a unique identifying key and that delete_requests contains all users that have requested deletion, which statement describes whether successfully executing the above logic guarantees that the records to be deleted are no longer accessible and why?
- A. No; the Delta Lake delete command only provides ACID guarantees when combined with the merge into command.
- B. No; the Delta cache may return records from previous versions of the table until the cluster is restarted.
- C. No; files containing deleted records may still be accessible with time travel until a vacuum command is used to remove invalidated data files.
- D. Yes; Delta Lake ACID guarantees provide assurance that the delete command succeeded fully and permanently purged these records.
- E. Yes; the Delta cache immediately updates to reflect the latest data files recorded to disk.
Answer: C
Explanation:
Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from Explanation:
The code uses the DELETE FROM command to delete records from the users table that match a condition based on a join with another table called delete_requests, which contains all users that have requested deletion. The DELETE FROM command deletes records from a Delta Lake table by creating a new version of the table that does not contain the deleted records. However, this does not guarantee that the records to be deleted are no longer accessible, because Delta Lake supports time travel, which allows querying previous versions of the table using a timestamp or version number. Therefore, files containing deleted records may still be accessible with time travel until a vacuum command is used to remove invalidated data files from physical storage.
NEW QUESTION # 50
The data governance team is reviewing user for deleting records for compliance with GDPR. The following logic has been implemented to propagate deleted requests from the user_lookup table to the user aggregate table.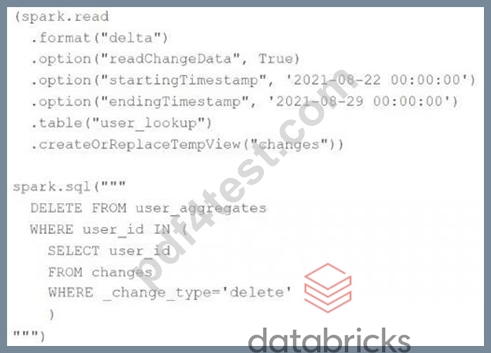
Assuming that user_id is a unique identifying key and that all users have requested deletion have been removed from the user_lookup table, which statement describes whether successfully executing the above logic guarantees that the records to be deleted from the user_aggregates table are no longer accessible and why?
- A. No; the change data feed only tracks inserts and updates not deleted records.
- B. Yes; the change data feed uses foreign keys to ensure delete consistency throughout the Lakehouse.
- C. No; the Delta Lake DELETE command only provides ACID guarantees when combined with the MERGE INTO command
- D. Yes; Delta Lake ACID guarantees provide assurance that the DELETE command successed fully and permanently purged these records.
- E. No; files containing deleted records may still be accessible with time travel until a BACUM command is used to remove invalidated data files.
Answer: E
Explanation:
Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from Explanation:
The DELETE operation in Delta Lake is ACID compliant, which means that once the operation is successful, the records are logically removed from the table. However, the underlying files that contained these records may still exist and be accessible via time travel to older versions of the table. To ensure that these records are physically removed and compliance with GDPR is maintained, a VACUUM command should be used to clean up these data files after a certain retention period. The VACUUM command will remove the files from the storage layer, and after this, the records will no longer be accessible.
NEW QUESTION # 51
Although the Databricks Utilities Secrets module provides tools to store sensitive credentials and avoid accidentally displaying them in plain text users should still be careful with which credentials are stored here and which users have access to using these secrets.
Which statement describes a limitation of Databricks Secrets?
- A. Because the SHA256 hash is used to obfuscate stored secrets, reversing this hash will display Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from the value in plain text.
- B. Account administrators can see all secrets in plain text by logging on to the Databricks Accounts console.
- C. The Databricks REST API can be used to list secrets in plain text if the personal access token has proper credentials.
- D. Iterating through a stored secret and printing each character will display secret contents in plain text.
- E. Secrets are stored in an administrators-only table within the Hive Metastore; database administrators have permission to query this table by default.
Answer: C
Explanation:
This is the correct answer because it describes a limitation of Databricks Secrets. Databricks Secrets is a module that provides tools to store sensitive credentials and avoid accidentally displaying them in plain text. Databricks Secrets allows creating secret scopes, which are collections of secrets that can be accessed by users or groups. Databricks Secrets also allows creating and managing secrets using the Databricks CLI or the Databricks REST API. However, a limitation of Databricks Secrets is that the Databricks REST API can be used to list secrets in plain text if the personal access token has proper credentials. Therefore, users should still be careful with which credentials are stored in Databricks Secrets and which users have access to using these secrets.
NEW QUESTION # 52
All records from an Apache Kafka producer are being ingested into a single Delta Lake table with the following schema:
key BINARY, value BINARY, topic STRING, partition LONG, offset LONG, timestamp LONG There are 5 unique topics being ingested. Only the "registration" topic contains Personal Identifiable Information (PII). The company wishes to restrict access to PII. The company also wishes to only retain records containing PII in this table for 14 days after initial ingestion.
However, for non-PII information, it would like to retain these records indefinitely.
Which of the following solutions meets the requirements?
- A. Data should be partitioned by the topic field, allowing ACLs and delete statements to leverage partition boundaries.
- B. Separate object storage containers should be specified based on the partition field, allowing isolation at the storage level.
- C. All data should be deleted biweekly; Delta Lake's time travel functionality should be leveraged to maintain a history of non-PII information.
- D. Because the value field is stored as binary data, this information is not considered PII and no special precautions should be taken.
- E. Data should be partitioned by the registration field, allowing ACLs and delete statements to be set for the PII directory.
Answer: A
Explanation:
By default partitionning by a column will create a separate folder for each subset data linked to the partition.
NEW QUESTION # 53
Two of the most common data locations on Databricks are the DBFS root storage and external object storage mounted with dbutils.fs.mount().
Which of the following statements is correct?
- A. The DBFS root stores files in ephemeral block volumes attached to the driver, while mounted directories will always persist saved data to external storage between sessions.
- B. Neither the DBFS root nor mounted storage can be accessed when using %sh in a Databricks notebook.
- C. By default, both the DBFS root and mounted data sources are only accessible to workspace administrators.
- D. DBFS is a file system protocol that allows users to interact with files stored in object storage using syntax and guarantees similar to Unix file systems.
- E. The DBFS root is the most secure location to store data, because mounted storage volumes must have full public read and write permissions.
Answer: D
Explanation:
DBFS is a file system protocol that allows users to interact with files stored in object storage using syntax and guarantees similar to Unix file systems. DBFS is not a physical file system, but a layer over the object storage that provides a unified view of data across different data sources. By Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from default, the DBFS root is accessible to all users in the workspace, and the access to mounted data sources depends on the permissions of the storage account or container. Mounted storage volumes do not need to have full public read and write permissions, but they do require a valid connection string or access key to be provided when mounting. Both the DBFS root and mounted storage can be accessed when using %sh in a Databricks notebook, as long as the cluster has FUSE enabled. The DBFS root does not store files in ephemeral block volumes attached to the driver, but in the object storage associated with the workspace. Mounted directories will persist saved data to external storage between sessions, unless they are unmounted or deleted.
NEW QUESTION # 54
A Spark job is taking longer than expected. Using the Spark UI, a data engineer notes that the Min, Median, and Max Durations for tasks in a particular stage show the minimum and median time to complete a task as roughly the same, but the max duration for a task to be roughly 100 times as long as the minimum.
Which situation is causing increased duration of the overall job?
- A. Network latency due to some cluster nodes being in different regions from the source data
- B. Spill resulting from attached volume storage being too small.
- C. Task queueing resulting from improper thread pool assignment.
- D. Credential validation errors while pulling data from an external system.
- E. Skew caused by more data being assigned to a subset of spark-partitions.
Answer: E
Explanation:
This is the correct answer because skew is a common situation that causes increased duration of the overall job. Skew occurs when some partitions have more data than others, resulting in uneven distribution of work among tasks and executors. Skew can be caused by various factors, such as skewed data distribution, improper partitioning strategy, or join operations with skewed keys. Skew can lead to performance issues such as long-running tasks, wasted resources, or even task failures due to memory or disk spills.
NEW QUESTION # 55
A junior developer complains that the code in their notebook isn't producing the correct results in the development environment. A shared screenshot reveals that while they're using a notebook versioned with Databricks Repos, they're using a personal branch that contains old logic. The desired branch named dev-2.3.9 is not available from the branch selection dropdown.
Which approach will allow this developer to review the current logic for this notebook?
- A. Use Repos to pull changes from the remote Git repository and select the dev-2.3.9 branch.
- B. Use Repos to make a pull request use the Databricks REST API to update the current branch to dev-2.3.9
- C. Use Repos to merge the current branch and the dev-2.3.9 branch, then make a pull request to sync with the remote repository
- D. Merge all changes back to the main branch in the remote Git repository and clone the repo again
- E. Use Repos to checkout the dev-2.3.9 branch and auto-resolve conflicts with the current branch
Answer: A
Explanation:
This is the correct answer because it will allow the developer to update their local repository with the latest changes from the remote repository and switch to the desired branch. Pulling changes will not affect the current branch or create any conflicts, as it will only fetch the changes and not merge them. Selecting the dev-2.3.9 branch from the dropdown will checkout that branch and display its contents in the notebook.
NEW QUESTION # 56
The security team is exploring whether or not the Databricks secrets module can be leveraged for connecting to an external database.
After testing the code with all Python variables being defined with strings, they upload the password to the secrets module and configure the correct permissions for the currently active Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from user. They then modify their code to the following (leaving all other variables unchanged).
Which statement describes what will happen when the above code is executed?
- A. The connection to the external table will succeed; the string value of password will be printed in plain text.
- B. The connection to the external table will succeed; the string "redacted" will be printed.
- C. An interactive input box will appear in the notebook; if the right password is provided, the connection will succeed and the encoded password will be saved to DBFS.
- D. An interactive input box will appear in the notebook; if the right password is provided, the connection will succeed and the password will be printed in plain text.
- E. The connection to the external table will fail; the string "redacted" will be printed.
Answer: B
Explanation:
This is the correct answer because the code is using the dbutils.secrets.get method to retrieve the password from the secrets module and store it in a variable. The secrets module allows users to securely store and access sensitive information such as passwords, tokens, or API keys. The connection to the external table will succeed because the password variable will contain the actual password value. However, when printing the password variable, the string "redacted" will be displayed instead of the plain text password, as a security measure to prevent exposing sensitive information in notebooks.
NEW QUESTION # 57
......
Pass Guaranteed Quiz 2025 Realistic Verified Free Databricks: https://validtorrent.pdf4test.com/Databricks-Certified-Data-Engineer-Professional-actual-dumps.html